Data Imbalance
Data imbalance occurs when the distribution of classes in a classification problem is skewed, meaning one class has significantly more samples than the others. Using data imbalance approaches, the platform is able to achieve better generalisation and improved predictive performances across classes.
Use Data Imbalance Options in evoML
- Navigate to New Trial
- Under Data Splitting, choose Data Imbalance Options. The available imbalance options:
- None (default)
- Auto
- SMOTE
- Borderline SMOTE
- SMOTE Tomek
- SVM SMOTE
- Adaptive Synthetic Sampling
- Random Oversampling
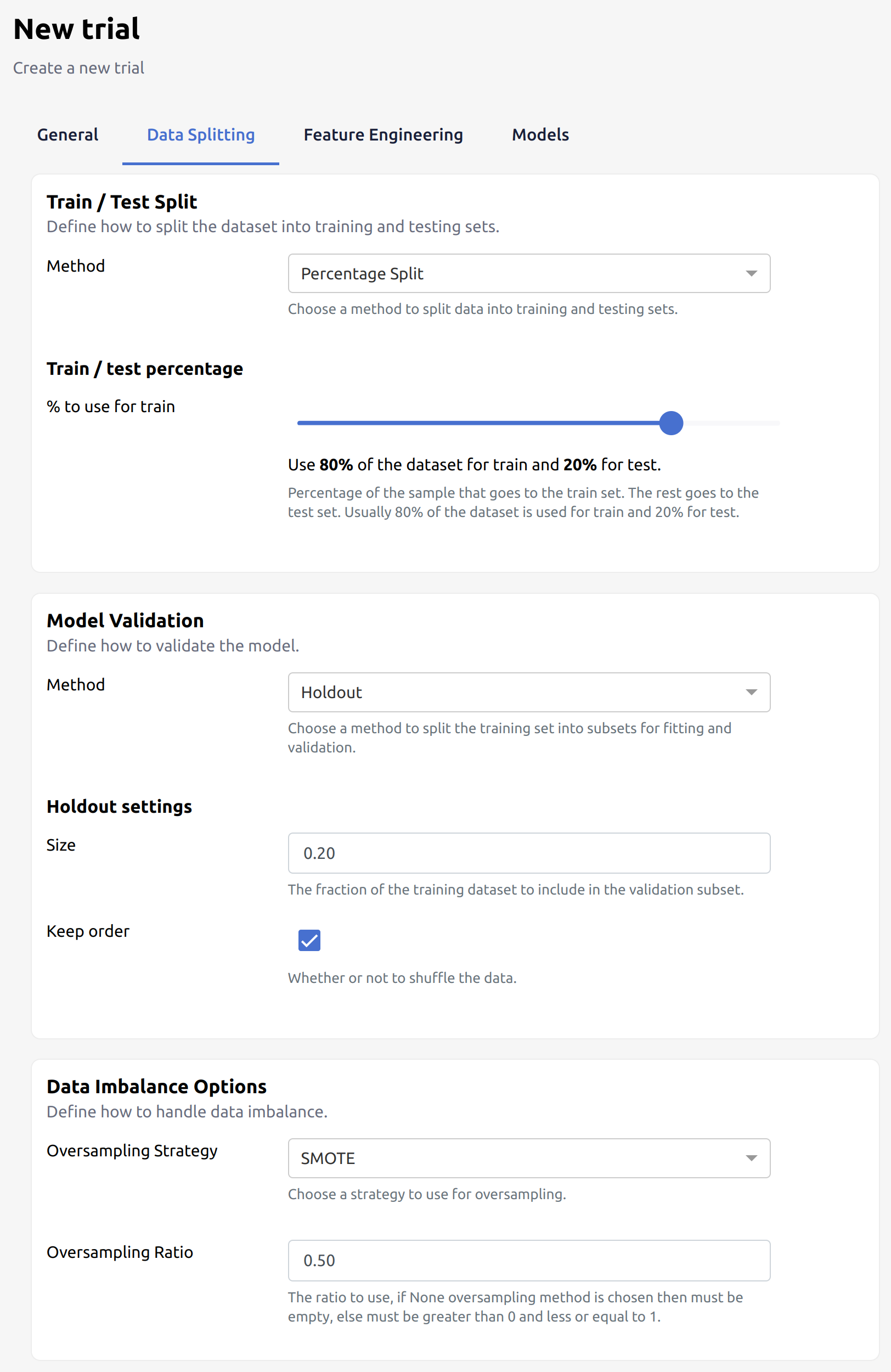
Imbalance Options
There are several options for handling imbalanced data:
- None: No resampling is applied to the dataset. By default, evoML doesn't perform oversampling.
- Auto: EvoML automatically selects the most appropriate sampling method based on the dataset characteristics.
- SMOTE (Synthetic Minority Over-sampling Technique): Creates synthetic examples of the minority class to balance the dataset.
- Borderline SMOTE: A variation of SMOTE that focuses on generating synthetic samples near the decision boundary.
- SMOTE Tomek: Combines SMOTE oversampling with Tomek links undersampling to clean the resulting distribution.
- SVM SMOTE: Uses Support Vector Machines to generate synthetic samples.
- Adaptive Synthetic Sampling (ADASYN): Similar to SMOTE but focuses on generating samples near the decision boundary.
- Random Oversampling: Randomly duplicates examples from the minority class
Sampling Ratio determines the degree of oversampling applied to the minority class.
- A ratio of 0 means no oversampling is performed.
- A ratio of 1 means the minority class will be oversampled to match the size of the majority class, resulting in a balanced dataset.
- A value between 0 and 1 represent partial oversampling of the minority class.