Splitting
Splitting a dataset ensures that we can train a model on one portion of the data and evaluate its performance on another, unseen portion. The platform provides multiple options for splitting datasets into training and test sets.
Select Splitting Options in evoML
- Navigate to New Trial
- Select Data Splitting
- Choose one of the splitting methods and configure the settings:
- Percentage split
- Split by index
- Use custom test dataset
Splitting Methods
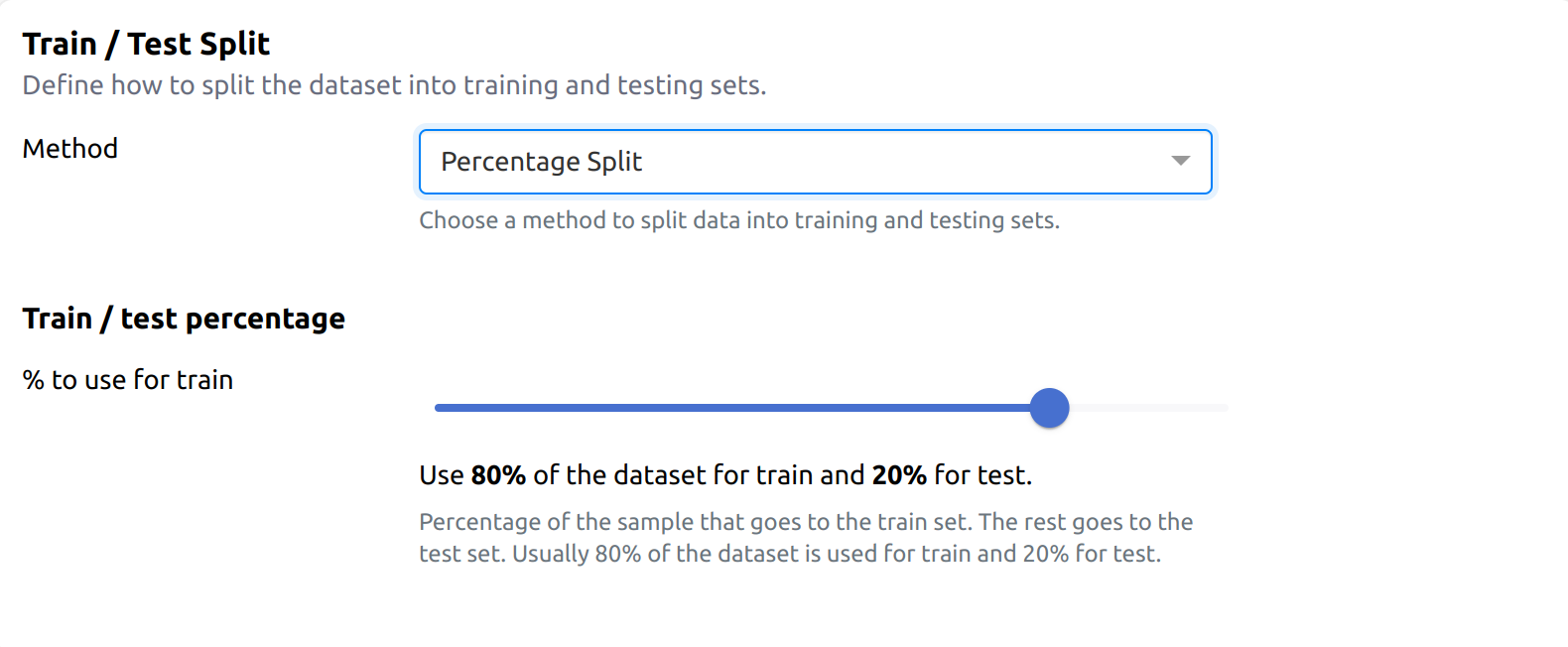
1. Percentage split
In this method, the dataset is split based on a percentage of the original dataset.
- By default, 80% of the dataset is used for training, and 20% is reserved for testing.
- This is the most commonly used splitting method for general machine learning tasks.
Example: If your dataset has 10,000 records, evoML will allocate 8,000 for training and 2,000 for testing (with the default 80/20 split).
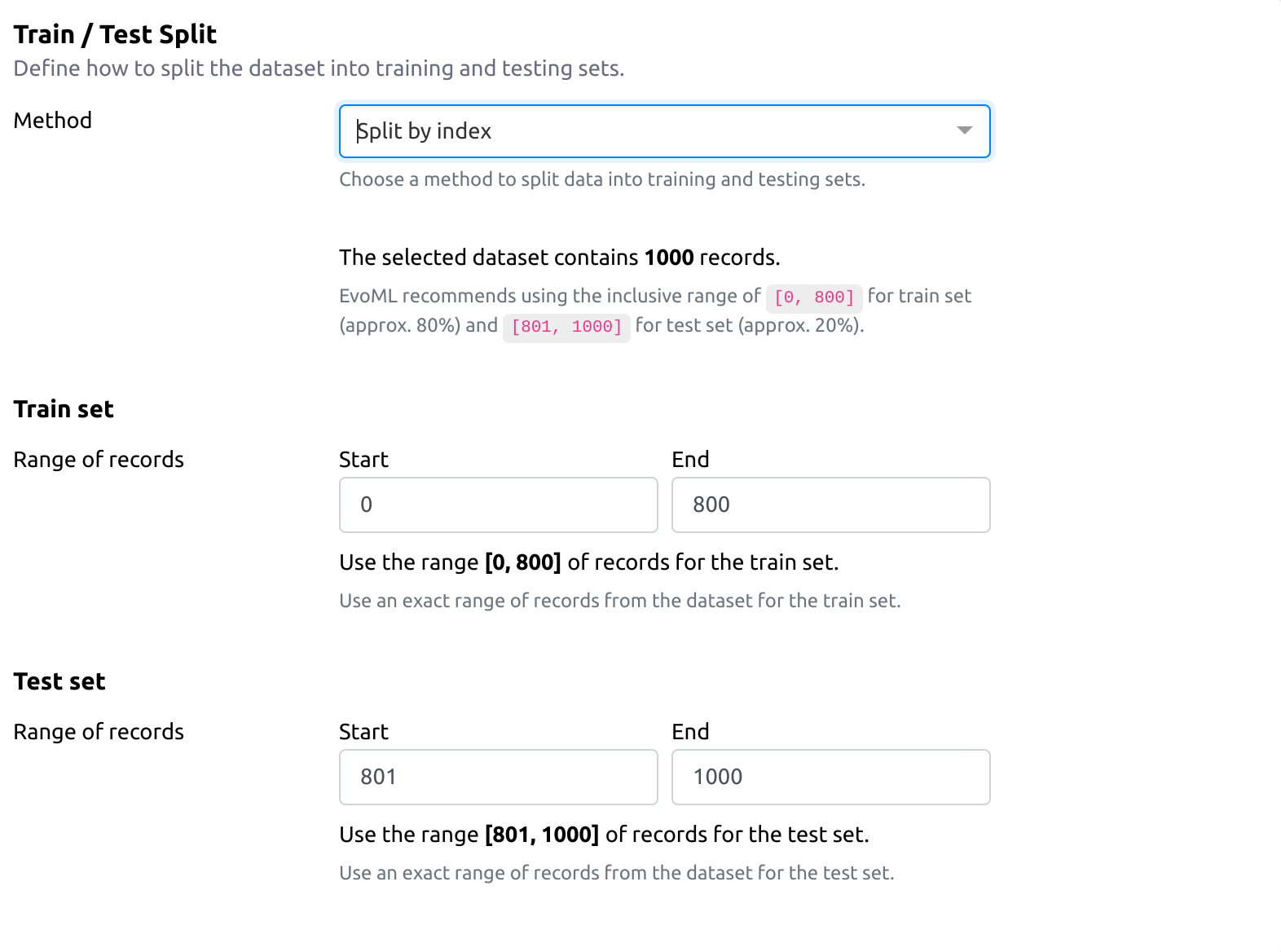
2. Split by index
This method splits the dataset based on a specific number of records.
- The first X records (as defined by the user) are assigned to the training set.
- The remaining records are assigned to the test set.
- This method is useful when dealing with time-series data, where earlier records are used for training and later records for testing.
Example: If you set X = 7,000 for a dataset with 10,000 records, the first 7,000 records will be used for training, and the remaining 3,000 for testing.
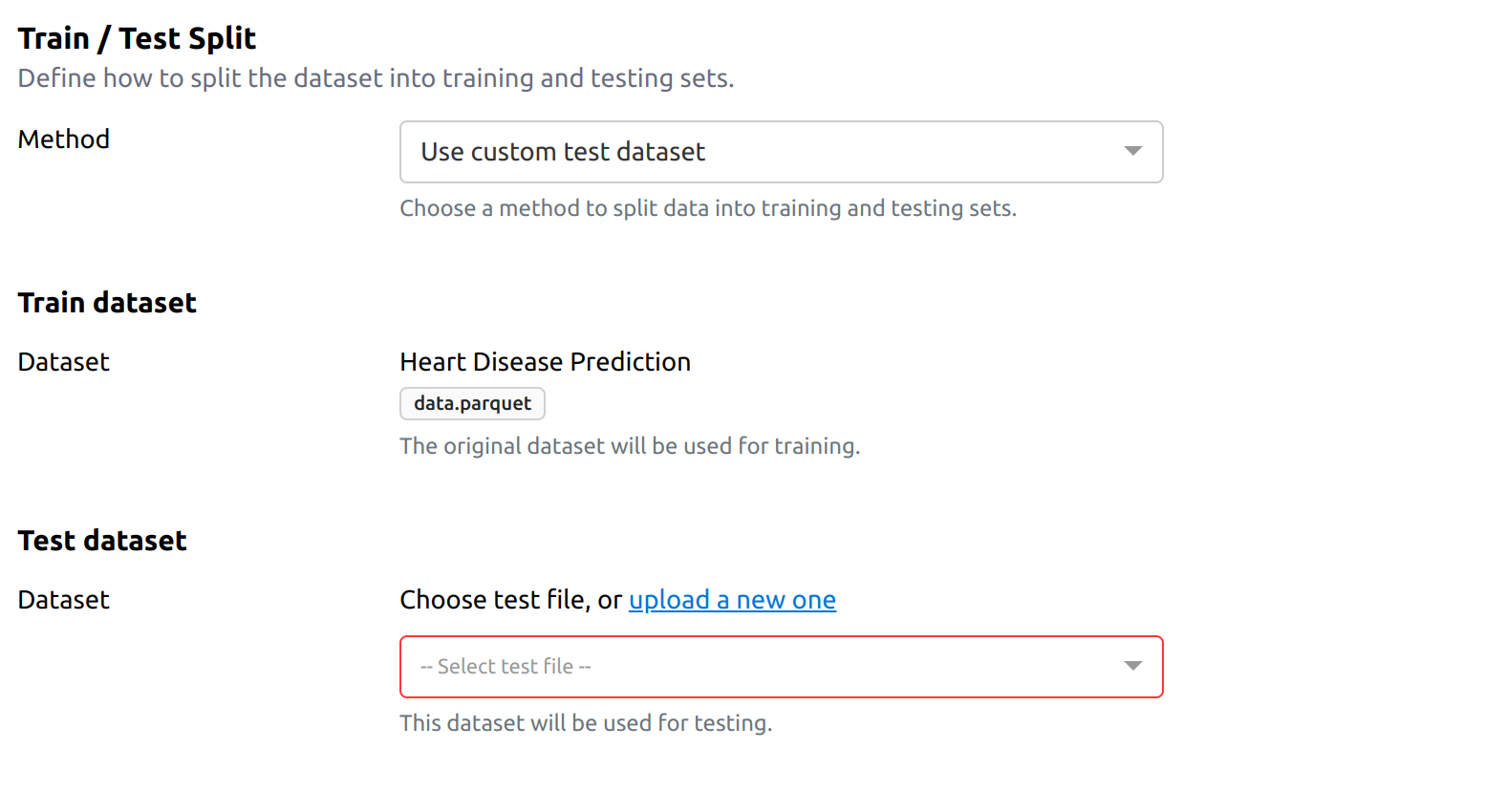
3. Use custom test dataset
With this option, the entire original dataset is used for training, while a separate dataset is used for testing.
- Useful when you have a pre-defined test dataset that differs from the training dataset.
- Ensures that training data remains intact while evaluating on a separate dataset.
Example: You might train a model on Dataset A and test it on Dataset B, ensuring the model generalizes well to new data.